Passionate about Linux, infrastructure, and real-world IT challenges, I love finding practical solutions and pushing systems to their limits – sometimes even breaking them on purpose just to see what happens. Whether I’m building high-availability platforms, automating tasks, or experimenting with new technology, I’m always up for a challenge.
This is a post I’ve wanted to write for a long time. It’s a look at how I designed and managed the network for a 120-player LAN party. The focus is networking, with server bits only where they actually matter for the network.
If you want the complete story end-to-end, this covers planning, hardware choices, and lessons learned. Some deep-dive technical details will be split into side posts; think of this as the A→Z overview.
Introduction
Over the past few years, I’ve organized four consecutive editions of a LAN party called JVLAN, here in Switzerland. The event grew steadily, and each edition taught me something new about running large-scale gaming networks.
Gamers are demanding: low latency, high bandwidth, and high PPS (packets per second). With each edition, the network design evolved to meet that.
Terms used in this post
Edge → gear directly facing players
Core → backbone gear players don’t touch
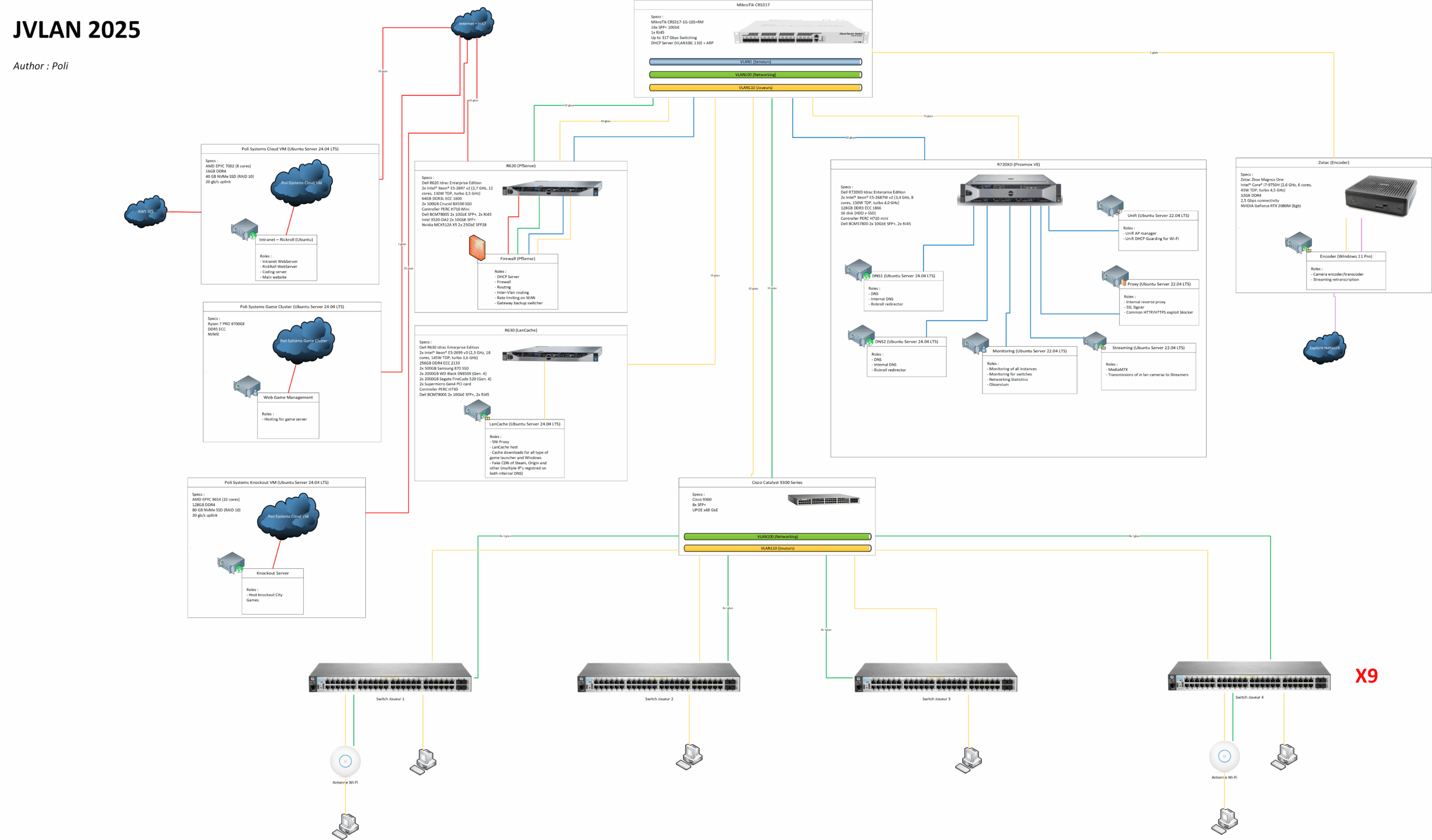
Schema: network diagram (press on it to see as PDF)
Planning & Sizing
The first constraint in any nowadays LAN is the uplink.
Edition 1: ~40 players, 1 Gbps line (small town). Went better than expected — lesson: you don’t always need “overkill” bandwidth if design is solid.
Edition 2: ~100 players, 25 Gbps from ISP partner Init7.
Edition 3: 120 players (≥120 PCs). To absorb unpredictable usage (e.g., 300 GB patches), we kept 25 Gbps from Init7.
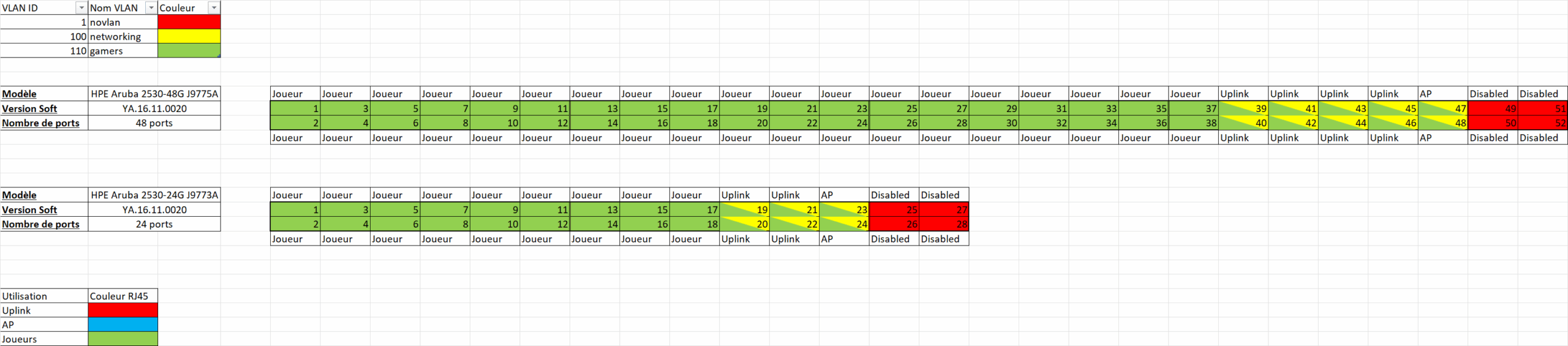
Ports & Cabling
120 players ≠ “just 120 ports”.
~90 cm desk space per player
With 10 m mandatory patch cables, you might cram ~40 players per switch on paper, but it’s not comfortable or practical
We targeted ~28 players / edge switch for margin and cable management
Final count (budget-aware):
8 Edge switches (players, staff, stage, etc.)
4 Core switches (2 active + 2 backup)
Hardware
Hybrid fiber + copper to keep costs sane (full fiber would be nice, but not at our budget).
3× UniFi AC Pro (Wi-Fi 5) — for consoles/staff/devices, not for PC gaming.
Firewall & Routing (High-Level)
We used pfSense. Pushing many multi-Gbps flows isn’t “plug-and-play” at 25 Gbps on BSD firewalls; you need proper NICs and OS tuning.
Two viable topologies:
One strong firewall, tuned
Several appliances behind an aggregating/TSNR router (each ~10 Gbps)
Init7 could have boosted to 100 Gbps, but our usage and hardware didn’t require it. 25 Gbps was enough.
Firewall Hardware Setup
Repurposed Dell PowerEdge servers:
Dell R620 — 2× Xeon E5-2697 v2, 64 GB RAM
NICs
NVIDIA Mellanox ConnectX-5 (2× SFP28) → uplinks
Intel X520-DA2 (2× SFP+) → switch
Dell BMC (2× SFP+) → unused
In practice, WAN tops around ~20 Gbps due to bonding/NIC/switch constraints — perfectly fine and gives headroom.
VLANs
Keep it simple (especially for game discovery).
VLAN 1: Internal servers
VLAN 100: Network management
VLAN 110: Players
If attendance grows, we’ll split players across multiple VLANs to reduce broadcast/mDNS/LLMNR/SSDP noise.
Traffic Shapping (pfSense vs OPNsense)
Event #1 was on OPNsense over a 1 Gbps line — smooth, but we needed Traffic Shapping. With ~40 people, unmanaged downloads/streams would spike latency.
Per-service QoS wasn’t realistic for a LAN (unknown apps).
I started with ALTQ Traffic Shapping and PRIQ → not ideal.
Switched to Limiters with CoDel (Controlled Delay) — killed bufferbloat and was fair.
CoDel (plain words): keeps queues short by dropping early under pressure, and fairly shares bandwidth across active flows (on 1 Gbps, 2 big downloaders ≈ 500/500; 3 ≈ 333 each, etc.). Set limiter slightly under real line rate and ping stays low even when saturated. With ~40 people, we averaged ~400 Mbps with peaks — CoDel was perfect.
When we moved to 25 Gbps, different story. I first tried CoDel again, ran into old FreeBSD constraints (historically ~4.25 Gbps per queue). Whether fixed or not, with 25 Gbps headroom we simply dropped Traffic Shapping — we didn’t need it.
We also tested a MikroTik CCR2004 in between (ISP → pfSense → CCR2004 “as a switch”), but using a router as a pure L2 switch was awkward; I only got ~17 Gbps due to how I bridged it then. We moved to the CRS; worked fine. The CRS310 doesn’t support SFP28, so we bonded 10 Gbps links → ~20 Gbps effective WAN.
pfSense vs OPNsense: I like OPNsense a lot, it improved fast, is stable and is simply great. At that time, pfSense + Mellanox hit higher throughput after tuning. I spent days tweaking OPNsense and couldn’t match it (likely driver differences). Today they may be on par; we kept pfSense pragmatically.
Firewall Policy (Intent)
Allow “like at home” web use with guardrails
Block obvious NSFW domains/lists (mixed platforms like Reddit/Discord are harder)
Avoid abusive traffic from our public IP (keep ISP happy). VPN/Tor tolerated; WAN data not on “our network”
Minimal inter-VLAN (DNS, reverse proxy, streaming, specific servers)
Keep a “prison” traffic shaping bucket ready for noisy IPs
DNS Policy & DoH
We run internal DNS (AdGuard) for policy/local resolution and want everyone to use it.
We block these ports so clients can’t bypass local DNS:
53 (DNS)
853 (DNS over TLS)
8853 (DNS over QUIC)
5353 (mDNS across segments)
DoH rides on 443, so you can’t blanket-block it without breaking the web.
Pure IP blocking for big DoH providers worked early on, until CDNs (e.g., Cloudflare “any service on any edge”) made IPs ambiguous.
Better: DoH bootstrap usually starts with a port 53 lookup for the DoH hostname — we don’t answer those for known defaults.
Also block major browsers’ default DoH providers directly in AdGuard.
Reverse NAT for DNS (the “magic”)
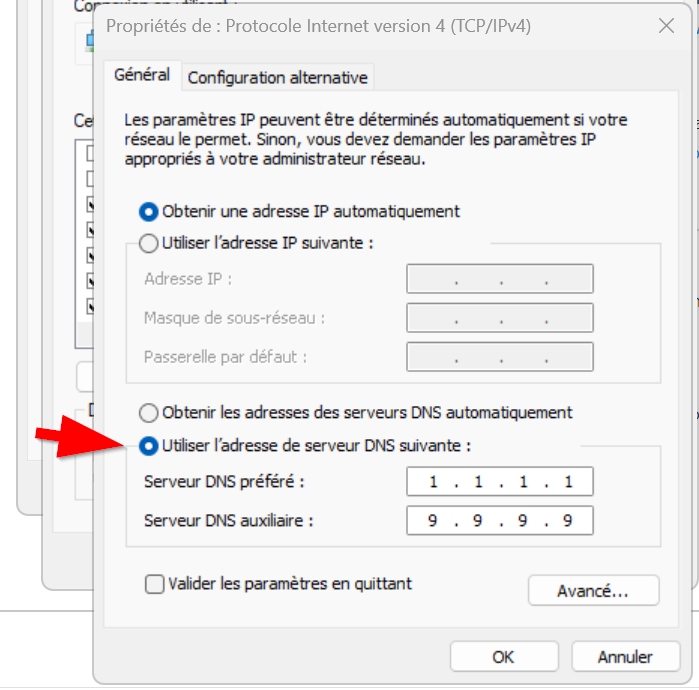
Some users can be hard-coding DNS 1.1.1.1 or 8.8.8.8 in their config, and if we don’t redirect the DNS port, it will simply drop the traffic and the player will come to us to say “Internet is down”. Before dropping :53, add a LAN-side NAT that redirects all outbound :53 → our DNS. Their resolver “works,” but responses come from us. It silently enforces local DNS and avoids helpdesk noise.
Example (conceptual pf rule — adapt to your interfaces): PLAYER LAN-> any dst port 53 rdr-to <adguard_ip>:53
kern.ipc.nmbclusters=10000000 → huge mbuf pool for high-bandwidth packet buffers
hw.ibrs_disable=1 → disable Spectre v2 mitigation (more perf, less security; acceptable for this isolated event role)
net.isr.dispatch=deferred → defer packet processing to threads (better multi-core scaling)
Remote pre-staging via OpenVPN (game downloads, last-minute configs). Other NATs only where needed.
Switching & DHCP (Together)
We don’t run DHCP on pfSense. Reason: I want ARP enforcement at the switch layer.
DHCP runs on a Core MikroTik at the top of the infra
Serves VLAN 110 (players) and VLAN 100 (management)
VLAN 1 (servers) is static
Uplinks & LACP
Edge is gigabit, so we bring multiple copper uplinks per edge switch (4–8 Gbps typical). On JVLAN 3 player rows we had 8×1 Gbps (25 m each; total cabling >1 km). Fiber would be nicer but out of budget.
We aggregate with LACP (L2) on edge and core. Our goal was to aggregate capacity for many flows, not single-flow optimization.
IP Spoofing Protection (ARP Discipline)
MikroTik can auto-add a static ARP entry when it leases an IP. Combine that with per-port ARP=reply-only on access ports (not uplinks/management), and devices without a valid DHCP lease get no L2 replies.
Effect:
Fixed/manual IPs won’t talk → no conflicts with DHCP
Players must use DHCP
“Steal neighbor’s IP to make them lag” doesn’t work (it happened)
Only remaining trick is MAC spoofing an existing lease (affects one victim; traceable)
MikroTik DHCP (illustrative)
/ip dhcp-server add name=dhcp_players interface=vlan110 address-pool=pool_players add-arp=yes
/interface ethernet switch port set [find where !uplink] arp=reply-only
DHCP Snooping & Port-Up Delays
Rogue DHCP is common (VR routers, “gaming” Wi-Fi boxes).
Trust only uplink ports for DHCP
Enable ARP protect/trust where available
We also saw ~60 s delays for ports to come up — classic STP convergence. For end devices, mark ports as edge/port-fast. Then enable BPDU Guard so if a BPDU shows up on an edge port, it shuts immediately. BPDU basically is able to find out if the edge port is connected to a switch, and shuts it down.
Broadcast Limiting & IGMP
Single players VLAN = more L2 noise. We rate-limit broadcast on edge ports (e.g., cap ~1%) to prevent broadcast storms.
For multicast (launchers, discovery), enable IGMP Snooping (and IGMP Proxy where useful). On the Cisco core (Catalyst 9360) it was straightforward; defining IGMP properly on edges reduced multicast PPS across the fabric. We wanted first to do it on the Mikrotik or PfSense side but it was really complicated to setup, while with the Cisco it was simple command.
Servers
We run servers on-site and in the cloud to keep WAN usage under control and to scale cleanly.
Game Cluster — Ryzen 7 PRO 8700GE (Poli Systems infra)
Knockout VM — EPYC 9654 · 128 GB · NVMe · 20 Gbps
Each on-site server uplinks to the core at ~20 Gbps — plenty for our needs.
DNS Services (AdGuard)
Two Ubuntu VMs on the Proxmox host running AdGuard, with NSFW and DoH-provider block lists. Their upstream DNS is LanCache to keep content local when possible. Blocked lookups resolve to the reverse proxy IP.
Reverse Proxy
Fronts internal sites (Observium, UniFi, etc.) and simplifies TLS. Unknown internal hostnames landing here are redirected to the cloud RickRoll / Intranet box.
RickRoll / Intranet
This cloud VM hosts our website and internal management platform: announcements, “animations”, downloads/links, seating, rankings/points, etc. Built by the team.
When DNS blocks something, users land on a RickRollpage — intentionally loud so the message is clear: don’t browse shady stuff during the event.
LanCache
Critical piece. LanCache fakes being the content servers at the DNS level (Steam, Riot, EA/Origin, Windows Update…). Clients download from LanCache; LanCache fetches from the internet once and caches.
It is also our “Final” internal DNS, it then redirects all traffic to 1.1.1.3 (CloudFlare Family).
Typical WAN savings: 6–7 TB per event
Observed bursts: ~20 Gbps (can scale higher with more disks/NICs)
Faster installs for everyone; fewer WAN spikes
Monitoring
I’m busy during the event; Observium watches switches, servers, firewalls, APs. It alerts if something breaks and provides nice post-event graphs.
Streaming
The venue has two NDI cameras on a separate network. We run a small box on their network to transcode both and push them to our internal WHIP server (one port opened). Streamers reuse those feeds without hammering our WAN.
Game Services
Poli Systems provides cloud capacity for game servers with a admin UI per game. For Knockout City, we added a beefy dedicated VM. This avoids last-minute crunch and keeps services flexible.
Intranet System (Quick Overview)
We built our own system to run the event end-to-end: tickets → seating → announcements → tournaments → bar. Multi-game and intentionally simple.
Fun bit: the venue’s LED strips/screens had no API — their proposal was a physical button. We mounted a motor that pressed on their button on an Arduino with an HTTP API and NAT-exposed it for our cloud intranet server. Our intranet calls it to trigger a visual “alarm” across the room for announcements. Everyone notices.
Wrap-Up
Keep it simple where possible, strict where it matters — ARP discipline, DHCP snooping, basic filtering, and enough throughput so you don’t need fancy Traffic Shapping at 25 Gbps.
I watned to keep this blog post, minimal and quite simple. Since I have been doing this for now a few years some parts are surely missing or simplified.
I didn’t include full configs here. If you want example configs, tips, or to rent parts of the infra, reach out: [email protected].